ZFS and GlusterFS network storage
Category : How-to
 Since ZFS was ported to the Linux kernel I have used it constantly on my storage server. With the ability to use SSD drives for caching and larger mechanical disks for the storage arrays you get great performance, even in I/O intensive environments. ZFS offers superb data integrity as well as compression, raid-like redundancy and de-duplication. As a file system it is brilliant, created in the modern era to meet our current demands of huge redundant data volumes. As you can see, I am an advocate of ZFS and would recommend it’s use for any environment where data integrity is a priority.
Since ZFS was ported to the Linux kernel I have used it constantly on my storage server. With the ability to use SSD drives for caching and larger mechanical disks for the storage arrays you get great performance, even in I/O intensive environments. ZFS offers superb data integrity as well as compression, raid-like redundancy and de-duplication. As a file system it is brilliant, created in the modern era to meet our current demands of huge redundant data volumes. As you can see, I am an advocate of ZFS and would recommend it’s use for any environment where data integrity is a priority.
Please note, although ZFS on Solaris supports encryption, the current version of ZFS on Linux does not. If you are using ZFS on Linux, you will need to use a 3rd party encryption method such as LUKS or EcryptFS.
The problem with ZFS is that it is not distributed. Distributed file systems can span multiple disks and multiple physical servers to produce one (or many) storage volume. This gives your file storage added redundancy and load balancing and is where GlusterFS comes in.
GlusterFS is a distributed file system which can be installed on multiple servers and clients to provide redundant storage. GlusterFS comes in two parts:
- Server – the server is used to perform all the replication between disks and machine nodes to provide a consistent set of data across all replicas. The server also handles client connections with it’s built in NFS service.
- Client – this is the software required by all machines which will access the GlusterFS storage volume. Clients can mount storage from one or more servers and employ caching to help with performance.
The below diagram shows the high level layout of the storage set up. Each node contains three disks which form a RAIDZ-1 virtual ZFS volume which is similar to RAID 5. This provides redundant storage and allows recovery from a single disk failure with minor impact to service and zero downtime. The volume is then split into three sub volumes which can have various properties applied; for example, compression and encryption. GlusterFS is then set up on top of these 3 volumes to provide replication to the second hardware node. GlusterFS handles this synchronisation seamlessly in the background making sure both of the physical machines contain the same data at the same time.
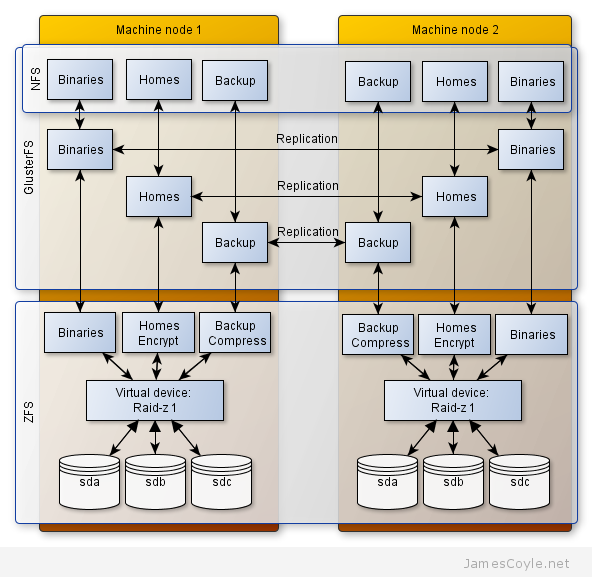
For this storage architecture to work, two individual hardware nodes should have the same amount of local storage available presented as a ZFS pool. On top of this storage layer, GlusterFS will synchronise, or replicate, the two logical ZFS volumes to present one highly available storage volume.
See this post for setting up ZFS on Ubuntu. For the very latest ZFS binaries, you will need to use Solaris as the ZFS on Linux project is slightly behind the main release. Set up ZFS on both physical nodes with the same amount of storage, presented as a single ZFS storage pool. Configure the required ZFS datasets on each node, such as binaries, homes and backup in this example. At this point, you should have two physical servers presenting exactly the same ZFS datasets.
We now need to synchronise the storage across both physical machines. In Gluster terminology, this is called replication. To see how to set up GlusterFS replication on two nodes, see this article.
These two technologies combined provide a very stable, highly available and integral storage solution. ZFS handles disk level corruption and hardware failure whilst GlusterFS makes sure storage is available in the event a node goes down and load balancing for performance.
17 Comments
Aaron Toponce
3-Sep-2013 at 11:02 amThere is no native encryption with the ZFS on Linux port. You’ll want to update your post. You can use LUKS or EcryptFS, but that’s outside of ZFS.
james.coyle
6-Sep-2013 at 8:12 pmThanks, Aaron. I did notice this in my tests however encryption is available in ZFS on Solaris.
Article updated to reflect – thanks!
Owes Khan
26-Sep-2013 at 10:48 pmThanks for the very informative post, we are in process of deploying some clustered storage servers and will definitely try GlusterFS on ZFS.
I am concerned about performance? Adding another layer (GlusterFs) would create overhead.
Did you notice any performance hit? We have several ZFS boxes deployed and the performance is pretty good, if the overhead is low then it would be great.
james.coyle
27-Sep-2013 at 4:24 pmHi Owes,
I did a post on performance and my experience with GlusterFS. There is some overhead, which can be quite sizeable with many small files. you’d expect this thouhg, and will experience the same performance penalty at the ZFS layer. It’s just life, unfortunately.
See http://www.jamescoyle.net/how-to/543-my-experience-with-glusterfs-performance
Gennady
9-Oct-2013 at 2:00 pmHi,
Just have one question:
when I extend a pool do I need to expect for any issue?
in ZFS it is very simple just add a device. But what would be a behavior when GlusterFS is over?
Thanks
james.coyle
9-Oct-2013 at 2:39 pmHi Gennady,
As GlusterFS just uses the filesystem and all it’s storage there should be no problem. As the zpool and the storage available to the GlusterFS brick increases GlusterFS will be able to consume the extra space as required.
I must be honest, I have not tested this yet so I’d be interested to know how you get on.
Faisal Reza
13-Dec-2013 at 4:29 amnice article
SAB
17-Feb-2014 at 12:49 amHi there
Thanks for this post
Is there any sync benchmark for small files (30 files @ avg 300kB in one dir.)
james.coyle
17-Feb-2014 at 8:40 amThat’s not a large enough section of data to make a worth-while benchmark.
Ideally you’d need to do 100s of files of that size to make a meaningful result.
Yannis M.
19-May-2014 at 9:35 amhello James,
Nice article. I’m also experimenting with a two-node proxmox cluster, which has zfs as backend local storage and glusterfs on top of that for replication.I have successfully done live migration to my vms which reside on glusterfs storage.
I want to ask your opinion about glusterfs and extended attributes on zfs.I read several articles on the inet which suggest to not use the combination of glusterfs + zfs and use glusterfs + xfs for better results.
james.coyle
20-May-2014 at 1:30 pmHi Yannis,
Do you have any links to these articles? I haven’t heard anything myself but it does sound interesting.
RangerRick
30-Aug-2014 at 9:16 pmWe have tried GlusterFS many times, but continue to hit the wall on performance not just with small files but with moderate numbers of files. For example, try running a filebench test (e.g., fileserver, randomrw, etc.) against a mirrored pair of GlusterFS on top of (any) filesystem, including ZFS. The network and filesystem are not the problem…
With one million files (a small number these days) and directories with moderately long filenames (less than 64 characters) with filebench, we have observed three (3) IOPS! You read that right – only three I/O per second!
We continue to try GlusterFS about every 6 months, hoping this file replication issue has been resolved, but no joy.
Attila Heidrich
25-Sep-2014 at 9:50 amWhat do you use then?
The problematic resource with 1M of files is a single directory, or a complete filesystem?
Lindsay Mathieson
13-Nov-2014 at 2:12 amThanks for the various articles on gluster, zfs and proxomox, they have been most helpful.
One of the big advantages Im finding with zfs, is how easy it makes adding SSD’s as journal logs and caches. I fiddled a lot with dm-cache, bcache and EnhanceIO – managed to wreck a few filesystems, before settling on zfs. Much better to have it integrated in the fs and of course the management/reporting tools are much better.
One thing – ZFS doesn’t support O_DIRECT, which can give you grief if running KVM images as by default they require direct access. You have to switch them to write through or write back caching before they will work.
And if you are running glusterfs on top of ZFS, hosting KVM images its even less obvious and you will get weird i/o errors until you switch the kvm to use caching.
Or you can follow the tuning guide here:
http://www.gluster.org/community/documentation/index.php/Libgfapi_with_qemu_libvirt#Tuning_the_volume_for_virt-store
That turns off glusters io cache which seems to insulate the VM’s from the lack of O_DIRECT, so you can leav the vm caching off.
Eric
23-Feb-2015 at 1:45 amHave you been able to create a gluster volume from a cifs-mounted zfs dataset?
Pepper
16-Jul-2018 at 7:35 pmHave you tried btrfs?
Hilne
6-Oct-2021 at 4:17 pmHi,
Thanks you for sharing your experience about GLUSTERFS over ZFS.
I want to do a feedback about my own experience.
I setup a three node GlusterFs cluster on OVH with sandbox VM (2GB ram and 1CPU).
I setup a disk of 50gb on each server and I configure zfs with RAID-0 and glusterfs with replication and no distribution.
Setup all with ansible-playbook and it worked fine untill I tested the performance for git clone, create file, rm file.
I got low performance like 6mn to touch 5000 files on glusterfs client whereas get 51s on NFS4 client (previous setup)
Create a large file is like the same performance as NFS
dd if=/dev/zero of=speetest bs=1M count=100 conv=fdatasync =~6MB/s
I tried to tune glusterfs server and read all forums / issues during three weeks and finally did a final test with Glusterfs recommanded Filesystem: xfs
Did test again and I got better results with create, rm file: 43s now
So I guess that was ZFS the problem but I can’t tell you why because I’m not an expert.
I read a lot of things about glusterfs low performance with handle many files so I thought it was glusterfs but no …
So if like me you have problems, just checkout the official glusterfs documentation:
https://gluster.readthedocs.io/en/latest/Install-Guide/Configure/
And if you have any answers about bad performance glusterfs over zfs, I can still make some test to understand why.
Thanks again for this !