In a previous blog post I detailed the steps involved in creating a new Docker container, making some changes and saving the image back to the local repository. The process described works well but it’s a very manual affair which Docker has a solution for.
In a previous blog post I detailed the steps involved in creating a new Docker container, making some changes and saving the image back to the local repository. The process described works well but it’s a very manual affair which Docker has a solution for.
Docker has a scripting language which can be used to create a new instance with a predefined list of commands and properties which will be used to create your new Docker instance.You could, for example, use a docker file to install Apache, configure the firewall and any further configurations we may need to make.
The benefits to using a Dockerfile, rather than making all the changes directly and saving the image are that the underlying OS and the additions that you wish to make are completely independent. You can, for example, run a Dockerfile on any OS image. Using the example that follows, you could run the Dockerfile on either a Debian or Ubuntu OS without changing a thing.
Create a directory to hold your DockerFile project, which we’ll call apache2 for this example. I’ll be placing all my DockerFiles in their own project directory under dockerfiles in my home directory.
mkdir -p /home/james/dockerfiles/apache2
Open a text file named Dockerfile in your favourite text editor in the project folder we just created. This is the standard file structure that Docker expects when creating DockerFiles.
vi /home/james/dockerfiles/apache2/Dockerfile
There are various commands we can use within a Dockerfile. The first command is the FROM statement which indicates which image should be used when creating your instance. I’m going to use the ubuntu image which I have previously downloaded to my local Docker server.
FROM ubuntu:14.04
Add MAINTAINER or author for the template. This is your name, username or whatever handle you’d like to be known as.
MAINTAINER James Coyle <[email protected]>
We are now going to use the RUN command to specify the commands that should be executed on the instance during creation. The commands will be executed in the order they appear in the Dockerfile. We will be installing Apache2 so we’ll be using the apt-get command to install.
RUN apt-get update
RUN apt-get upgrade -y
RUN apt-get install -y apache2
Next we’ll make a data directory on the host where we will keep our web files that are to be served by Apache.
RUN mkdir -p /data/apache/www
RUN chown -R root:www-data /data/apache/www
It’s a good idea to separate the Docker container from any user data so that a the container can be used for different purposes. What this mean in our example is that we will keep all the website data (HTML files, etc.) out of our container, leaving only the Apache software and general configuration within the container. This means that we can reuse our Docker image to create containers for other websites.
Using the Docker VOLUME command we can map a directory on the Docker host to a folder inside the container which will be configured once your container is created. The below example makes the directory /data/apache/www available for mapping later.
Add the VOLUME reference to your Dockerfile.
VOLUME /data/apache/www
We will need to be able to reach our container on port 80 so that we can use the Apache service over the network. Docker uses the EXPOSE command followed by a port number to allow incoming traffic to the container. Add the below entry to allow port 80.
EXPOSE 80
We now need to do some find and replace magic to change the Apache default site configuration to point to our new location, rather than the Apache default. This isn’t a Docker specific command, but is required for this example.
RUN sed -i 's#DocumentRoot /var/www#DocumentRoot /data/apache/www#' /etc/apache2/sites-available/000-default.conf
Finally we’ll need to tell Docker what should be executed in order to ‘run’ this container. For this example, we use the apache2ctl command with the FOREGROUND switch.
ENTRYPOINT /usr/sbin/apache2ctl -D FOREGROUND
And that’s it, your first DockerFile. Run your newly created DockerFile to build the image by changing to the project directory and using the docker build command to create it. Use the -t switch to specify a tag for the image.
cd /home/james/dockerfiles/apache2
docker build -t apache2:test .
It will take a few minutes for the image to build. Once complete, you’ll be able to see it in the Docker image list by using the command docker image.
root@docker:~/apache2# docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
apache2 test fdf56ad12ffa 4 minutes ago 228.2 MB
The whole DockerFile:
FROM ubuntu:14.04
MAINTAINER James Coyle <[email protected]>
RUN apt-get update
RUN apt-get upgrade -y
RUN apt-get install -y apache2
RUN mkdir -p /data/apache/www
RUN chown -R root:www-data /data/apache/www
VOLUME /data/apache/www
EXPOSE 80
RUN sed -i 's#DocumentRoot /var/www#DocumentRoot /data/apache/www#' /etc/apache2/sites-available/000-default.conf
ENTRYPOINT /usr/sbin/apache2ctl -D FOREGROUND
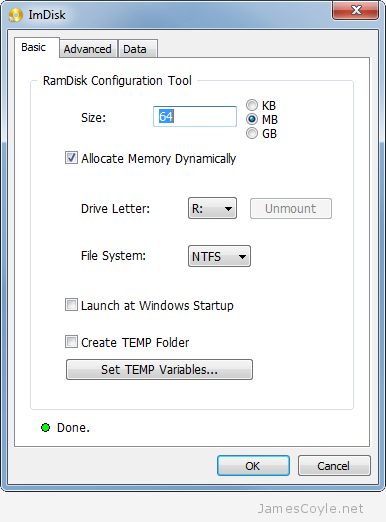
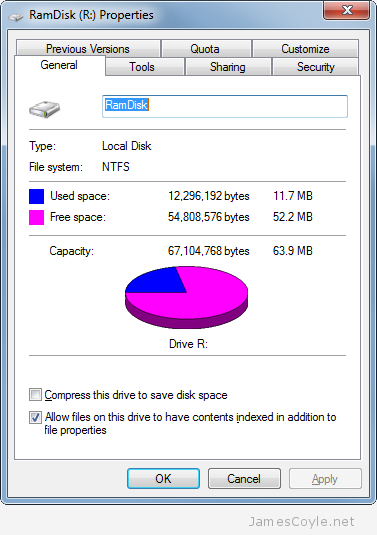
 I’ve been using RAM disks within Linux for quite some time now and I’ve blogged about it with the
I’ve been using RAM disks within Linux for quite some time now and I’ve blogged about it with the 
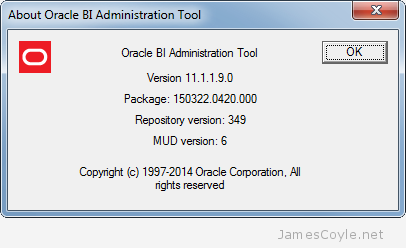
 An RPD file saved by one version of the OBIEE Administration Tool cannot be opened by an older version of the OBIEE Administration Tool or be applied to an older version of an Oracle BI Server. For this example we’re looking at an RPD created with version 349 of the Administration Tool (that’s the first release of OBIEE 11.1.1.9) and we’re trying to apply it to a server expecting version 326 (that’s the latest patched release of OBIEE 11.1.1.7.150120)
An RPD file saved by one version of the OBIEE Administration Tool cannot be opened by an older version of the OBIEE Administration Tool or be applied to an older version of an Oracle BI Server. For this example we’re looking at an RPD created with version 349 of the Administration Tool (that’s the first release of OBIEE 11.1.1.9) and we’re trying to apply it to a server expecting version 326 (that’s the latest patched release of OBIEE 11.1.1.7.150120)