Where to Run Ceph Processes For High Availability
Category : Knowledge
![]() In this blog post we’re going to take a detailed look at the Ceph server processes within a Ceph cluster of multiple server nodes.
In this blog post we’re going to take a detailed look at the Ceph server processes within a Ceph cluster of multiple server nodes.
Ceph is a highly available network storage layer that uses multiple disks, over multiple nodes, to provide a single storage platform for use over a network. Ceph is designed to be fault tolerant to ensure access to data is always available.
A Ceph cluster consists of 4 components:
- Monitor – is the daemon that holds the cluster map listing all the available nodes and Ceph daemons that are available for use by the cluster.
- OSD – is the daemon that handles the reading and writing of data to a physical disk. One OSD process will run per storage medium (usually a single disk device such as /dev/sdb) attached to the cluster. For example, a single server with 3 hard disks attached for use by the Ceph cluster will run 3 OSD processes.
- Metadata – is only required is Ceph will be used as a CephFS, that is a network filesystem. The Metadata, or MDS, daemon contains metadata on files and directories such as size and directory hierarchy so that Ceph can be used as a POSIX compliant filesystem. There can only be one active MDS daemon at any one time, but at least one secondary passive MDS daemon is advised to provide fault tolerance.
- Client – is used to read and write to the Ceph cluster. It allows the Linux kernel to mount a Ceph cluster as a filesystem, use Ceph as an object store or use Ceph as a block device.
Ceph Process Architecture
The Ceph storage daemons can run on dedicated hardware to provide a highly available file storage layer to remote clients over a network. This configuration is similar to a typical file server where the hardware is dedicated to only serving data. Extremely large or high performance storage requirements would usually be configured in this way to ensure there is sufficient resource (such as CPU, RAM and disk) to meet the requirements of the cluster. Ceph can also be used, in smaller and less demanding environments, to run alongside existing applications to maximise the use of existing hardware and reduce costs. This is one of the recommended setups for Proxmox VE, for example. The below example shows a 4 server cluster of Ceph daemons, suitable for either of the above two scenarios.
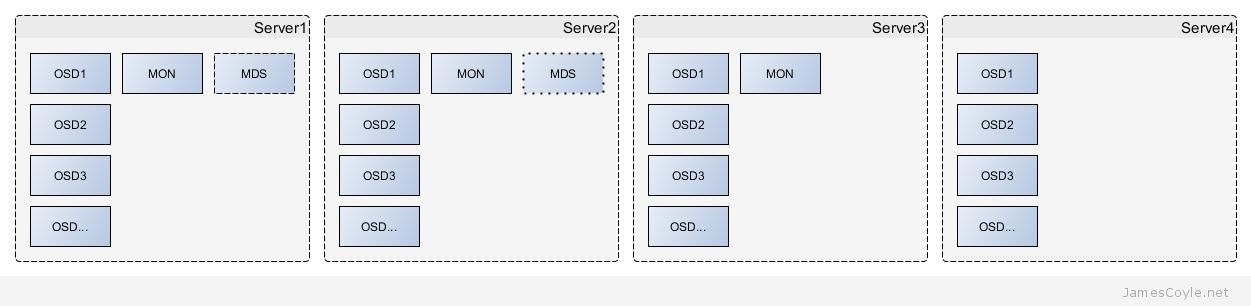
Server1 has 4 OSD processes running, which would indicate there are 4 physical disks used by Ceph on the server. The monitor daemon ensures that available nodes and daemons are tracked so that requests for I/ O can be served by active nodes. Finally, the optional MDS daemon is available and running for metadata requests from a Ceph filesystem. There can only be one active MDS daemon for a cluster, therefore server one hosts the primary MDS daemon.
Server2 is the same as Server1 however it’s MDS process is in standby mode. As only one MDS daemon can be answering requests at any given time, the MDS daemon runs in Active/ Passive mode. If the Active daemon fails, it takes around 30 seconds for the Passive daemon to become Active. This can present a small period of downtime for metadata requests. Future versions of Ceph will change this behaviour to create a more redundant process.
Server3 does not have any MDS component because there are already two nodes hosting an active and standby MDS process.
Server4 only hosts OSD processes. All other processes are already highly available and with a node of this size there is plenty of redundancy.
Scaling Ceph
Ceph is very modular by design, with each process having a specific task and talking to other processes over the network. Adding new servers is something that can be done easily, and without downtime to the existing storage pool. Further storage servers would look like either Server3 or Server4.
Generally additional servers are added so that more disks can be added to the cluster, and therefore it’s easy to understand why additional OSD processes would be added. In addition to adding additional servers (horizontal scaling), if existing servers have sufficient resource, further OSD processes could be added to the existing servers (vertical scaling). Adding additional OSD processes could be to either increase the overall storage pool size, increase the replication factor or to increase available bandwidth.
Mon processes, however, are not required on all servers and are only needed in multiples to prevent a failure causing downtime. Ceph requires a majority of monitors running to establish a quorum therefore monitors should always exist in odd numbers. To explain a little further; more monitor processes must be available then failed, for a cluster. So in a cluster with 10 monitor processes only 4 could fail before causing a problem, whereas with 11 monitor processes 5 could fail. Generally 3 mon processes will be sufficient for common Ceph cluster requirements.
Conclusion
Ceph should be provisioned to provide at least the minimum availability you need from your storage pool and the maximum risk you can afford to data loss. Each component must be balanced; it’s no good having a fully fault tolerant suite of monitor processes if you’ve not enabled data replication.
My final point is to plan for cluster maintenance as well as failures. Throughout a cluster’s lifetime, it’s reasonable to expect that individual servers will be taken out of service for short periods of time. For example, applying Ceph updates requires that the components are restarted, or applying kernel updates often results in a complete restart of the host taking several minutes to complete. During this time your cluster will be in a degraded state as services required by the cluster are offline. Ceph is designed to work in this scenario (depending on configuration) however if, for example, you only have 3 mon processes and you take the server down running one of them to apply a kernel update then the cluster cannot function if another mon process fails due to other reasons.