 I have been having trouble with a Proxmox node which is only running OpenVZ containers however it is at the upper limit of its RAM resources. Over time, I noticed that Proxmox used SWAP (virtual memory, page file, etc), quite aggressively, to make sure there was always some RAM free. That sounds fantastic, and is just what I would expect the Proxmox server to be doing, except it does it all too well. Proxmox made sure that around 40% of the RAM on the host machine was free at the expense of moving many running processes across all the running containers to SWAP. This is how Linux works, by design, and is expected behaviour. Running processes which have memory which hasn’t been touched in a while have their memory moved to SWAP. This allows other applications which need the memory right now to use it and anything left over can be used as cache by the kernel. When a process with memory in SWAP needs to use that memory, it needs to be read from SWAP and back into memory so that it can be used. There is a huge overhead with this process and will often be noticed when you use a container which has not been used in a while – at the start everything will be slow until all the required memory items have been read from SWAP and put back into RAM. To help with this situation we can do two things:
I have been having trouble with a Proxmox node which is only running OpenVZ containers however it is at the upper limit of its RAM resources. Over time, I noticed that Proxmox used SWAP (virtual memory, page file, etc), quite aggressively, to make sure there was always some RAM free. That sounds fantastic, and is just what I would expect the Proxmox server to be doing, except it does it all too well. Proxmox made sure that around 40% of the RAM on the host machine was free at the expense of moving many running processes across all the running containers to SWAP. This is how Linux works, by design, and is expected behaviour. Running processes which have memory which hasn’t been touched in a while have their memory moved to SWAP. This allows other applications which need the memory right now to use it and anything left over can be used as cache by the kernel. When a process with memory in SWAP needs to use that memory, it needs to be read from SWAP and back into memory so that it can be used. There is a huge overhead with this process and will often be noticed when you use a container which has not been used in a while – at the start everything will be slow until all the required memory items have been read from SWAP and put back into RAM. To help with this situation we can do two things:
- Make sure SWAP is always on a fast disk with plenty of free IO bandwidth. On a small installation, this should not be on the same disk as your container file systems. SSDs can also bring a huge performance benefit over conventional mechanical drives.
- Reduce the amount of RAM which Proxmox keeps free by making the algorithm which moves memory to SWAP less aggressive.
Move SWAP to fast storage
Generally, and when installing Proxmox for the first time a SWAP partition will be created on your hard disk. By default, this will be the same partition as your Proxmox operating system and your container storage. On a slow mechanical disk, this will result in far too much IO concurrency – that is different processes trying to read or write to a disk at the same time – which will massively affect server performance. One thing we can move to another disk is system wide swap.
You can either use a new file, disk, partition or block device for your new swap location. You will then need to turn your old SWAP device off to stop it from being used. Use the below examples to move your SWAP device.
See this post for a quick script to automatically create a SWAP file.
Make a new SWAP device as a file
Create a file on your file system and enable it to be used as a SWAP device. The below example uses the mount /mnt/swapdrive and the file swapfile to use as your new swap device with a size of 4096 MB.
dd if=/dev/zero of=/mnt/swapdrive/swapfile bs=1M count=4096
You will then need to format the file as SWAP with the below command.
mkswap /mnt/swapdrive/swapfile
Make a new SWAP device as a partition
Use the below command to use a drive partition as your new SWAP device. The below example uses /dev/sdc3 as your SWAP partition. You must have precreated this partition for it to be available.
mkswap /dev/sdc3
swapon /dev/sdc3
Turn a new SWAP device on
Once you have a new SWAP device created, either a file or a disk or partition you will need to enable it. Use the swapon command. The below shows an example of a file and disk partition command:
swapon /mnt/swapdrive/swapfile
swapon /dev/sdc3
Turn off the old SWAP device
To turn off the old SWAP device, first identify it using swapon -s.
swapon -s
Then, use the swapoff command to turn the device off. The below example is the default Proxmox SWAP device location.
swapoff /dev/mapper/pve-swap
Clear SWAP space without rebooting
You can clear your SWAP memory by turning the system wide SWAP memory off and then back on again. Run the below commands to turn off your system wide SWAP space forcing all the SWAP to be read back into RAM. You must have enough RAM for available on your system for this to work correctly. Once this has completed, run the second command to turn SWAP back on again. You can also use this to make your SWAP memory changes take effect.
swapoff -a
swapon -a
Make the SWAP file persist after rebooting
To make sure your SWAP file is mounted the next time your machine reboots you’ll need to add an entry to the fstab file.
Open the fstab file with your text editor:
vi /etc/fstab
And add a line, similar to the below making sure the first attribute is the location of your newly created SWAP file.
/mnt/swapdrive/swapfile swap swap defaults 0 0
Change the ‘swapiness’ setting
To change how aggressively Proxmox, or other Linux distribution, moves process memory to SWAP we have a swapiness attribute. The swapiness setting is a kernel setting which is permanently set in the /etc/sysctl.conf file, or temporarily using sysctl.
The swapiness setting takes a value between 0 and 100. Using 0 will virtually turn off using SWAP, except to avoid an out of memory exception (oom). Using a value of 100 will cause the system to use SWAP as often as possible and will likely degrade system performance servilely. A value of 60 is the default for Proxmox.
Change the swapiness value for the current boot
To change your swapiness value for the current boot, use the below command. The value will be reset after rebooting. The following example will set the swapiness value to 20.
sysctl -w vm.swappiness=20
Permanently change the swapiness value
Use the below command to permanently change your swapiness value. Note that this will not affect the current boot.
vi /etc/sysctl.conf
And add the following to give a swapiness of 20
vm.swappiness=20
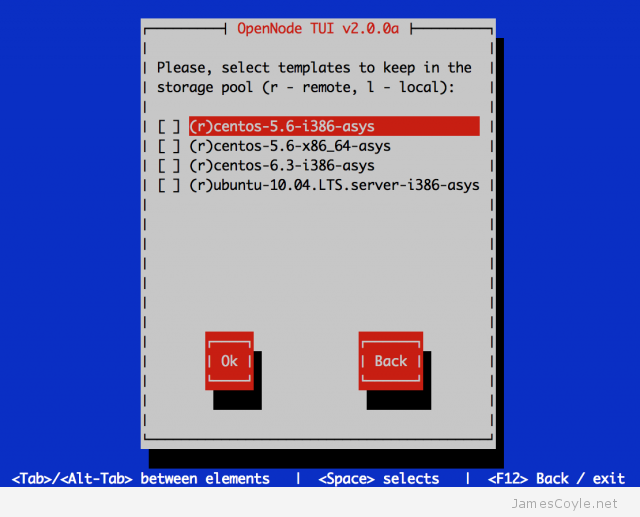
 Over the past few days I have been looking at alternative virtualisation servers to Proxmox VE, something which I have been using for the past few years. This has been prompted by Proxmox’ recent move to subscription based stable repositories and free test repositories. What this means is that unless I pay a subscription, I am no longer allowed to use the stable Proxmox binaries through apt-get and have to use potentially unsafe ‘test’ binaries. Of cause, I could build the latest stable binaries directly from git but then there is another problem – I don’t know what commit is marked as ‘stable’ to use as my build source.
Over the past few days I have been looking at alternative virtualisation servers to Proxmox VE, something which I have been using for the past few years. This has been prompted by Proxmox’ recent move to subscription based stable repositories and free test repositories. What this means is that unless I pay a subscription, I am no longer allowed to use the stable Proxmox binaries through apt-get and have to use potentially unsafe ‘test’ binaries. Of cause, I could build the latest stable binaries directly from git but then there is another problem – I don’t know what commit is marked as ‘stable’ to use as my build source.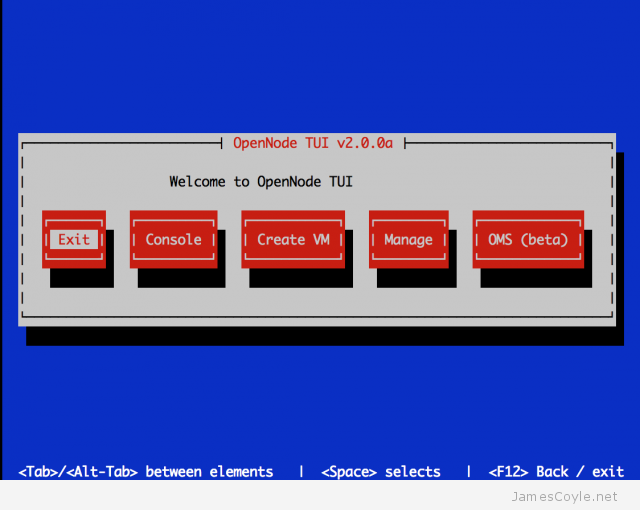
 I have been using GlusterFS to replicate storage between two physical servers for two reasons; load balancing and data redundancy. I use this on top of a ZFS storage array as described in
I have been using GlusterFS to replicate storage between two physical servers for two reasons; load balancing and data redundancy. I use this on top of a ZFS storage array as described in