My experience with GlusterFS performance.
Category : How-to
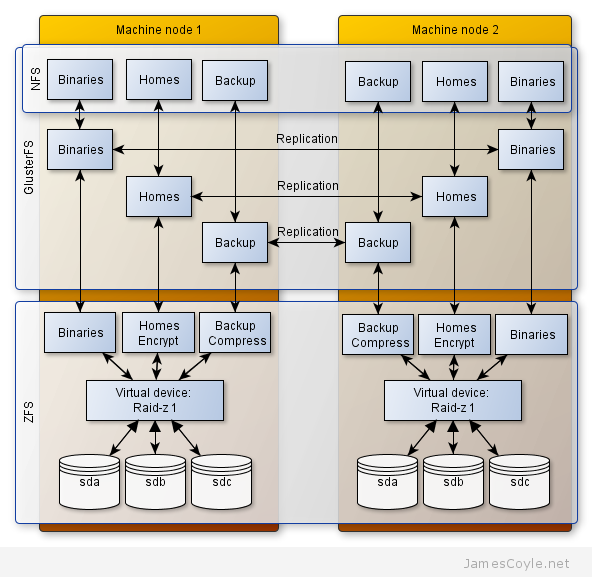
 I have been using GlusterFS to replicate storage between two physical servers for two reasons; load balancing and data redundancy. I use this on top of a ZFS storage array as described in this post and the two technologies combined provide a fast and very redundant storage mechanism. At the ZFS layer, or other filesystem technology that you may use, there are several functions that we can leverage to provide fast performance. For ZFS specifically, we can add SSD disks for caching, and tweak memory settings to provide the most throughput possible on any given system. With GlusterFS we also have several ways to improve performance but before we look into those, we need to be sure that is it the GlusterFS layer which is causing the problem. For example, if your disks or network is slow, what chance does GlusterFS have of giving you good performance? You also need to understand how the individual components work under the load of your expected environment. The disks may work perfectly well when you use dd to create a huge file, but what about when lots of users create lots of files all at the same time? You can break down performance into three key areas:
I have been using GlusterFS to replicate storage between two physical servers for two reasons; load balancing and data redundancy. I use this on top of a ZFS storage array as described in this post and the two technologies combined provide a fast and very redundant storage mechanism. At the ZFS layer, or other filesystem technology that you may use, there are several functions that we can leverage to provide fast performance. For ZFS specifically, we can add SSD disks for caching, and tweak memory settings to provide the most throughput possible on any given system. With GlusterFS we also have several ways to improve performance but before we look into those, we need to be sure that is it the GlusterFS layer which is causing the problem. For example, if your disks or network is slow, what chance does GlusterFS have of giving you good performance? You also need to understand how the individual components work under the load of your expected environment. The disks may work perfectly well when you use dd to create a huge file, but what about when lots of users create lots of files all at the same time? You can break down performance into three key areas:
- Networking – the network between each GlusterFS instance.
- Filesystem IO performance – the file system local to each GlusterFS instance.
- GlusterFS – the actual GlusterFS process.
Networking Performance
Before testing the disk and file system, it’s a good idea to make sure that the network connection between the GlusterFS nodes is performing as you would expect. Test the network bandwidth between all GlusterFS boxes using Iperf. See the Iperf blog post for more information on benchmarking network performance. Remember to test the performance over a period of several hours to minimise the affect of host and network load. If you make any network changes, remember to test between each change to make sure it has had the desired effect.
Filesystem IO Performance
Once you have tested the network between all GlusterFS boxes, you should test the local disk speed on each machine. There are several ways to do this, but I find it’s best to keep it simple and use one of two options; DD or bonnie++. You must be sure to turn off any GlusterFS replication as it is just the disks and filesystem which we are trying to test here. Bonnie++ is a freely available IO benchmarking tool. DD is a linux command line tool which can replicate data streams and copy files. See this blog post for information on benchmarking the files system.
Technology, Tuning and GlusterFS
Once we have made it certain in our minds that disk I/O and network bandwidth are not the issue, or more importantly understood what constraints they give you in your environment, you can tune everything else to maximise performance. In our case, we are trying to maximise GlusterFS replication performance over two nodes.
We can aim to achieve replication speeds nearing the speed of the the slowest performing speed; file system IO and network speeds.